【R】Tidymodelsで機械学習
1.はじめに
正直、良くわかっていないのですが、Julia SilgeさんのYoutubeの解説”Predictive modeling in R with tidymodels and NFL attendance”を見ていたら、わかったような錯覚に陥ったので、備忘録も兼ねて書いておきます。解説のほぼほぼ写しです。
RのパッケージTidyverseはデータハンドリングや可視化のツールとして認知されていますが、それと親和性が良い(?)Tidymodelsというパッケージがあります。
僕は、機械学習のことはほとんどわからないので、認識違いもたくさんありそうですが。
1.データの準備
2.モデルの学習
3.モデルの評価
をしていると思います。
2.データ準備
データは、TidyTuesdayという小規模カンファレンス(?)での課題データである米NFLフットボールのデータです。今回の解説では、このデータを用いて、いろいろな要素から週間観客数(weekly_attendance)を予測しようというものです(おそらく。これも違っていたらどうしよう。。。)。そもそもが、NFLのことをほとんど知らず、興味もないので、その点からして問題のような気がします。。。
ライブラリを準備します。僕の環境では、後々、ランダムフォレストのエンジンでrangerを使うのですが、rangerというパッケージをインストールしておかないとコードが動きませんでした。
library(tidyverse) library(tidymodels) library(ranger)
データを取得し、成形します。
attendance <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-04/attendance.csv')
standings <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-04/standings.csv')
games <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-04/games.csv')
attendance_joined<-attendance %>% left_join(standings, by = c("year", "team_name", "team"))
attendance_joined %>%
filter(!is.na(weekly_attendance)) %>%
ggplot(aes(fct_reorder(team_name, weekly_attendance),
weekly_attendance,
fill = playoffs)) +
geom_boxplot(outlier.alpha = 0.5) +
coord_flip()
成形したデータを色々確認してみます。まず、箱ひげ図でデータを確認してみます。
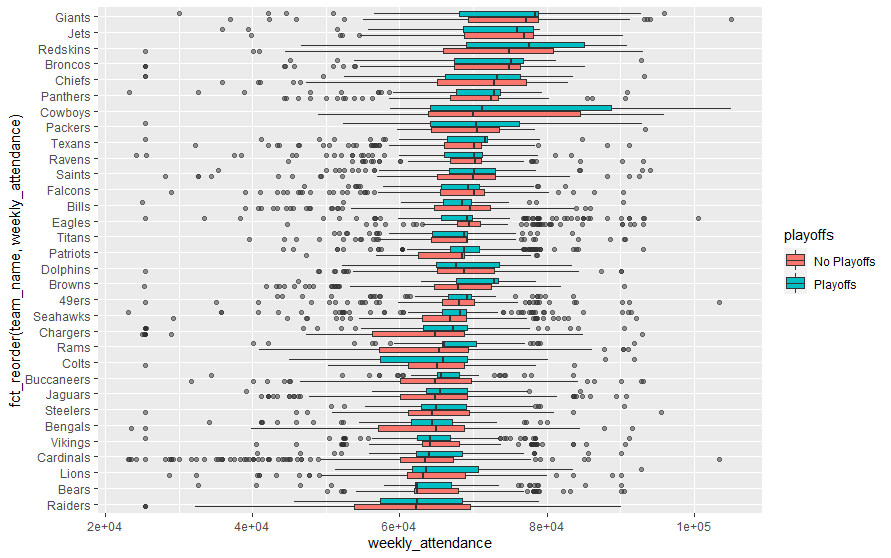
各チームごとの週間観客数をプレイオフあり/なしで表示しています。ここでは、週間観客数の順に並び変えています。次にmargin_of_victory(どれだけで優勝できるか、かな?)に対するヒストグラムを表示してみます。
attendance_joined %>% distinct(team_name, year, margin_of_victory, playoffs) %>% ggplot(aes(margin_of_victory, fill = playoffs)) + geom_histogram(position = "identity", alpha = 0.7 )
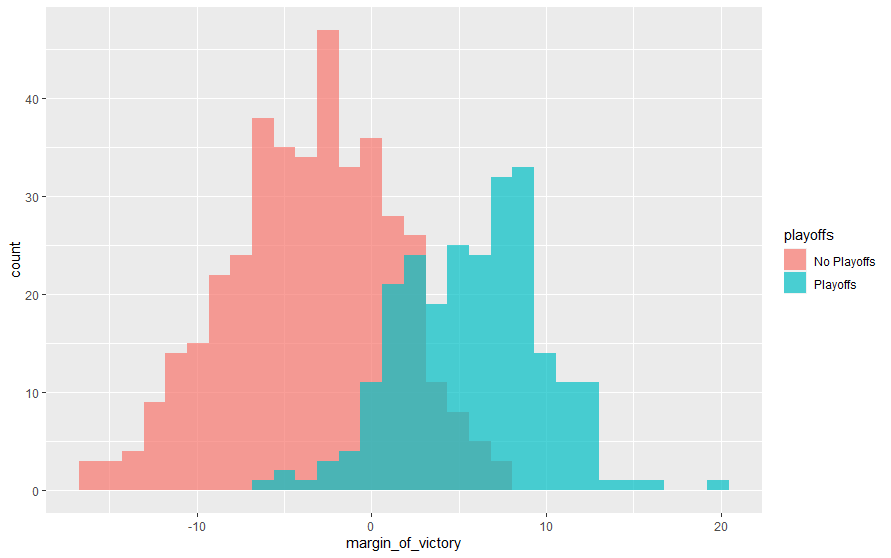
margin_of_victoryによって、分布が異なっていますので、予測する要素として使えそうです。最後に、週ごとの観客数を箱ひげ図で描いてみます。
attendance_joined %>% mutate(week = factor(week)) %>% ggplot(aes(week, weekly_attendance, fill = week)) + geom_boxplot(show.legend = FALSE, outlier.alpha = 0.4)
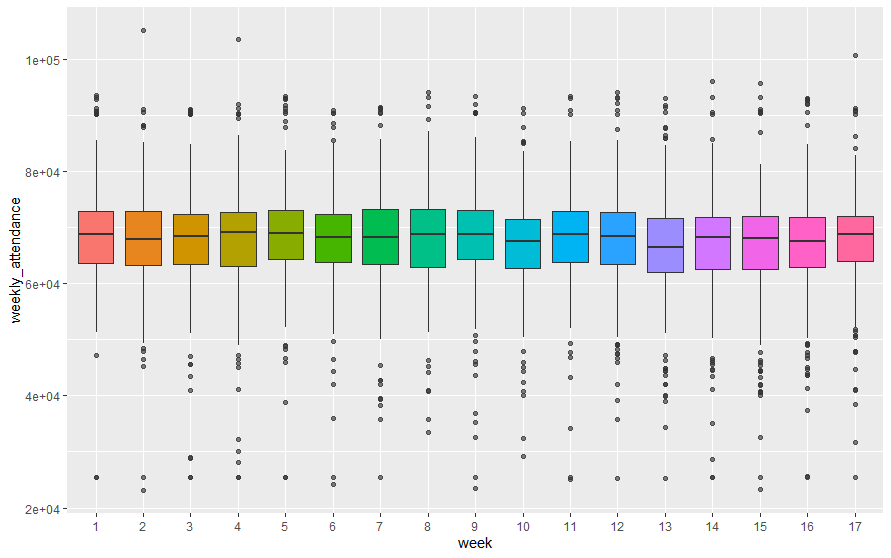
週ごとの差は小さいようです。若干下がり気味?以上の確認結果を踏まえ、週間観客数に影響を与えそうなパラメータだけのデータをattendance_dfとして再構築します。
# Model
attendance_df<-attendance_joined %>%
filter(!is.na(weekly_attendance)) %>%
select(weekly_attendance, team_name, year, week,
margin_of_victory, strength_of_schedule, playoffs)
3.機械学習モデル
3.1 トレーニングデータとテストデータ
準備したデータをトレーニングデータnfl_trainとテストデータnfl_testに、initial_split関数を使い、分割します。。
set.seed(1234) attendance_split<-attendance_df %>% initial_split(strata = playoffs) nfl_train<-training(attendance_split) nfl_test<-testing(attendance_split)
それぞれ、以下のようになります。
> head(nfl_train)
# A tibble: 6 x 7
weekly_attendance team_name year week margin_of_victory strength_of_schedule playoffs
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 77434 Cardinals 2000 1 -14.6 -0.7 No Playoffs
2 66009 Cardinals 2000 2 -14.6 -0.7 No Playoffs
3 71801 Cardinals 2000 4 -14.6 -0.7 No Playoffs
4 66985 Cardinals 2000 5 -14.6 -0.7 No Playoffs
5 44296 Cardinals 2000 6 -14.6 -0.7 No Playoffs
6 38293 Cardinals 2000 7 -14.6 -0.7 No Playoffs
> head(nfl_test)
# A tibble: 6 x 7
weekly_attendance team_name year week margin_of_victory strength_of_schedule playoffs
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 65356 Cardinals 2000 12 -14.6 -0.7 No Playoffs
2 50289 Cardinals 2000 14 -14.6 -0.7 No Playoffs
3 37452 Cardinals 2000 16 -14.6 -0.7 No Playoffs
4 65711 Cardinals 2000 17 -14.6 -0.7 No Playoffs
5 73025 Falcons 2000 3 -10.1 1.5 No Playoffs
6 66019 Falcons 2000 7 -10.1 1.5 No Playoffs3.2 機械学習モデル
モデルは、線形回帰(Linear regression)とランダムフォレストの2つを作って比較してみます。モデル化に使うパッケージをset_engine()で指定して、学習はfit()で完了です。
まずは、Linear regressionです。
lm_spec<-linear_reg() %>%
set_engine(engine = "lm")
lm_fit<-lm_spec %>%
fit(weekly_attendance ~ .,
data = nfl_train) # get 1st model (Liner model)
次にランダムフォレストです。
rf_spec<-rand_forest(mode="regression") %>%
set_engine("ranger")
rf_fit<-rf_spec %>%
fit(weekly_attendance ~ .,
data = nfl_train) # get 2nd model (Random forest model)
4.機械学習モデルの評価
テストデータを使った予測は、predict()で行います。予め言っておくと、コメントにも書いてありますが、このモデル(というか、データ)は良くありませんでした。。。。あとでわかったことですが。これには、Juliaさんも苦笑い(笑)。とにかく、進みます。
# Evaluate model
# not great choices
result_train<-lm_fit %>%
predict(new_data = nfl_train) %>%
mutate(truth = nfl_train$weekly_attendance,
model = "lm") %>%
bind_rows(rf_fit %>%
predict(new_data = nfl_train) %>%
mutate(truth = nfl_train$weekly_attendance,
model = "rf"))
result_test<-lm_fit %>%
predict(new_data = nfl_test) %>%
mutate(truth = nfl_test$weekly_attendance,
model = "lm") %>%
bind_rows(rf_fit %>%
predict(new_data = nfl_test) %>%
mutate(truth = nfl_test$weekly_attendance,
model = "rf"))
この結果を、rms(root mean square)で評価します。
result_train %>% group_by(model) %>% rmse(truth = truth, estimate = .pred)
# A tibble: 2 x 4
model .metric .estimator .estimate
<chr> <chr> <chr> <dbl> rmse root mean squre
1 lm rmse standard 8343. <- train と test でほぼ同じ
2 rf rmse standard 6106.<- train と test で異なる(悪い)本来は良いはずresult_test %>% group_by(model) %>% rmse(truth = truth, estimate = .pred)
# A tibble: 2 x 4 #model .metric .estimator .estimate #<chr> <chr> <chr> <dbl> # 1 lm rmse standard 8239. # 2 rf rmse standard 8627.
上のコメントにも書きましたが、lmモデルよりrfモデルの方がrmsが大きくなってしまいました。本来なら、ランダムフォレストの方が精度が良いはずなのですが。
で、どういうことが起こったのか、プロットして確認します。
result_test %>%
mutate(train = "testing") %>%
bind_rows(result_train %>%
mutate(train = "training")) %>%
ggplot(aes(truth, .pred, color = model)) +
geom_abline(lty = 2, color = "gray80", size = 1.5) +
geom_point(alpha = 0.5) +
facet_wrap(~train)
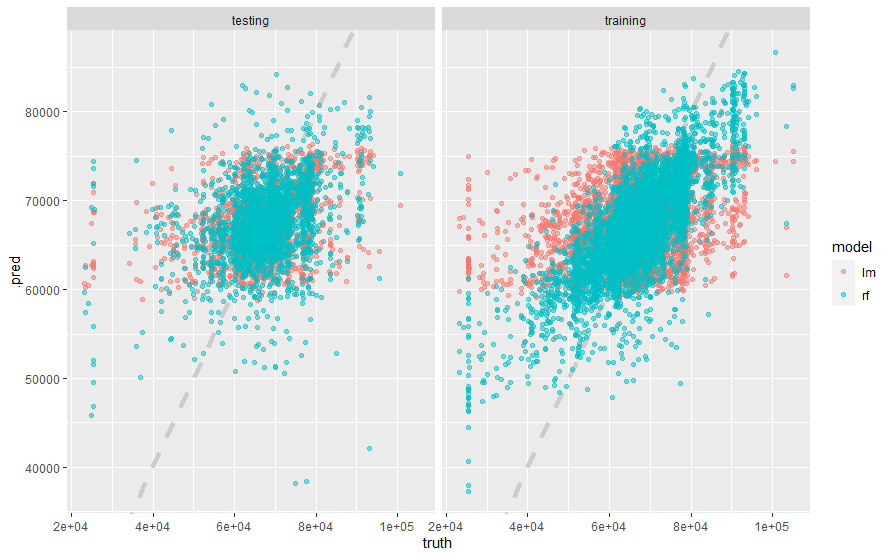
確かに、ランダムフォレストの方が当てはまりが悪い。。。
で、ここからが理解できなかったのですが、何やらデータがおかしいとか。。。再度、チャレンジすることにしました。
5.機械学習モデル 再び
5.1 データ修正(?)
## Let's try again! # better choices # Resampling training data to get better estimate set.seed(1234) nfl_folds<-vfold_cv(nfl_train, strata = playoffs) rf_res<-fit_resamples( rf_spec, weekly_attendance ~ ., resamples = nfl_folds, control = control_resamples(save_pred = TRUE) )
5.2 もう一回学習(?)
rf_res %>% collect_metrics()
# > rf_res %>%
# + collect_metrics()
# A tibble: 2 x 5
.metric .estimator mean n std_err
<chr> <chr> <dbl> <int> <dbl>
1 rmse standard 8258. 10 114.
2 rsq standard 0.164 10 0.009575.3 再度の学習の成果を
# visualisation rf_res %>% unnest(.predictions) %>% ggplot(aes(weekly_attendance, .pred, color = id )) + geom_abline(lty = 2, color = "gray80", size = 1.5) + geom_point(alpha = 0.5)
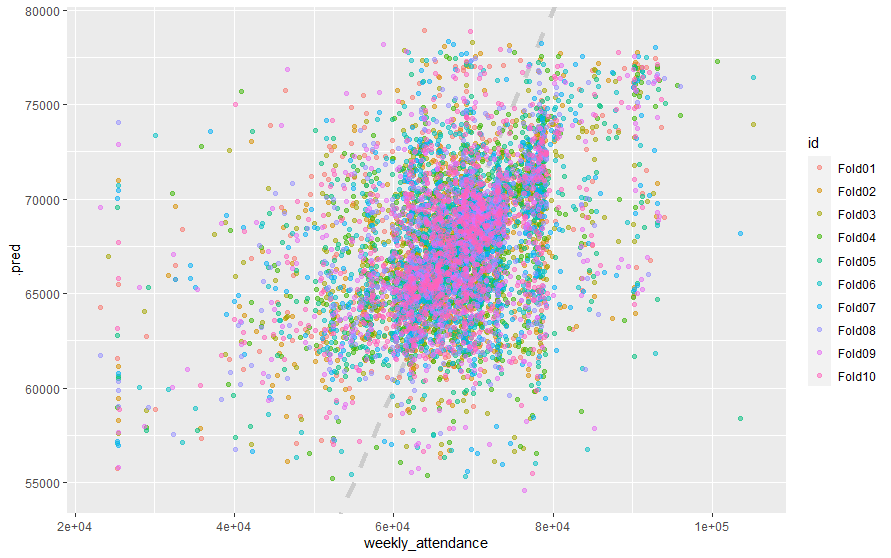
これは、当てはまりがいい!
6.さいごに
何となく、機械学習についてわかった気がする。Rのパッケージを使うと簡単なような気がする。でも、最後が良くわからなかったので、いつか復習したい。今回のところは、何となく分かっただけでも満足。
NFLの事をあまりに知らなかったので、こちらの公式サイトも見ました。また、Tidymodelsに関しては、こちらのサイトも参考にさせていただきました。
