【R】Tesseract OCR engine
2020年7月8日
1. はじめに
画像に書かれている文字を手入力で一つ一つデータ化することは大変ですよね。これを何かの方法で手早くできたらいいなあ。って思います。
こんな時はOCRがいいのですが、Rでもできます!
今回は、Tesseracr OCR engineを使ってみます。「Using the Tesseract OCR engine in R」のページを参考にしました。
2. インストール
CRANからインストールします。
install.packages("tesseract")読み取るデータは、Wikipediaから拝借。日本についてのページの冒頭です。日本語と英語で試してみます。
3. 使ってみる
3.1 まずは英語で
まずは、比較的簡単であろう英語から。
library(tesseract)
eng <- tesseract("eng")
text <- tesseract::ocr("Japan_en.PNG", engine = eng)
cat(text)
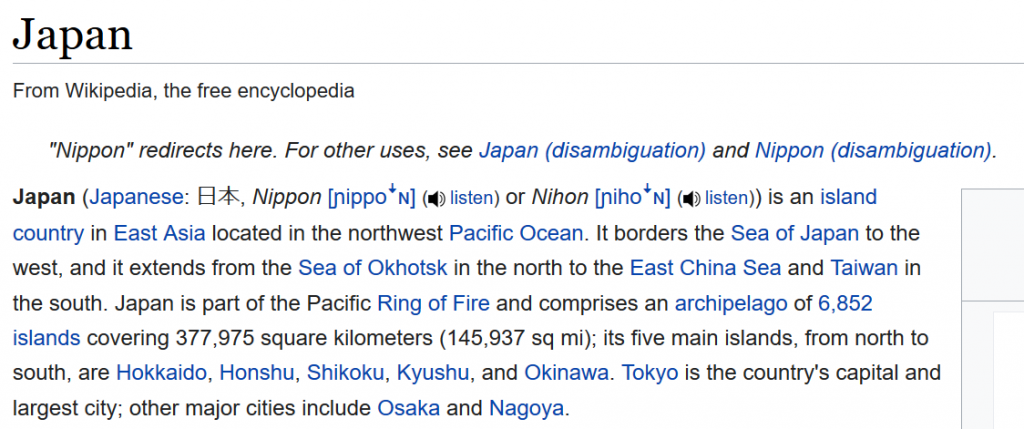
Japan
From Wikipedia, the free encyclopedia
"Nippon" redirects here. For other uses, see Japan (disambiguation) and Nippon (disambiguation).
Japan (Japanese: HA, Nippon [nippo*n] (® listen) or Nihon [niho*n] (@ listen)) is an island
country in East Asia located in the northwest Pacific Ocean. It borders the Sea of Japan to the
west, and it extends from the Sea of Okhotsk in the north to the East China Sea and Taiwan in
the south. Japan is part of the Pacific Ring of Fire and comprises an archipelago of 6,852
islands covering 377,975 square kilometers (145,937 sq mi); its five main islands, from north to
south, are Hokkaido, Honshu, Shikoku, Kyushu, and Okinawa. Tokyo is the country's capital and
largest city; other major cities include Osaka and Nagoya.おお!ちゃんと文章をデータとして出力しています。しかも正確。
3.2 日本語では?
次に日本語ではどうでしょう?
まずは、日本語のエンジンを入れる必要があります。
> tesseract_download("jpn")
Downloaded: 2.36 MB (100%)で、実行してみます。
jpn <- tesseract("jpn")
text <- tesseract::ocr("Japan_ja.PNG", engine = jpn)
cat(text)
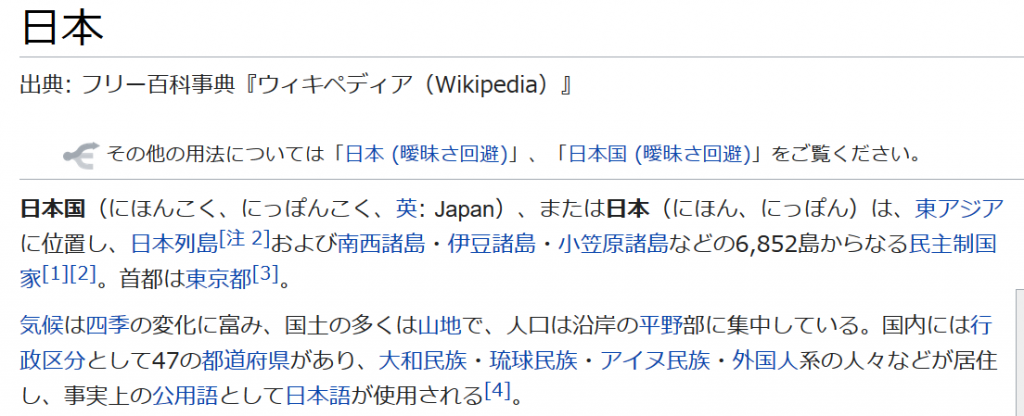
出典: フリー百科事典『ウィキペディア (Wikipedia) 』
その他の用法については 「日本 (曖昧さ回避)」、「日本国 (曖昧さ回避)」をご覧ください。
日本国 (にほんごく、にっぽんごく、英: Japan) 、または日本 (にほん、につっぽん) は、東アジア
に位置し、日本列島[注 21および南西諸島・伊豆諸島・小笠原諸島などの6,852島からなる民主制国
家H1[2]。 首都は東京者3]。
気候は四季の変化に富み、国士の多くは山地で、人口は沿岸の平野部に集中している。国内には行
政区分として47の都道府県があり、大和民族・琉球民族・アイヌ民族・外国人系の人々などが居住
し、事実上の公用語として日本語が使用される[41。一部、間違いがありますが、十分です。これは便利!
4. 最後に
今回は、きれいなデータでしたのでOCRは簡単だったかもしれません。見にくかったり掠れていたりノイズが多いと正確な読み取りはより難しくなるでしょう。それでも、人間の助けになるには十分だと思います。
