【R】ggplotをキレイに
2020年7月10日
ggplotできれいなグラフを描きましょう的な備忘録です。
The Evolution of a ggplot (Ep. 1)のページを参考に勉強してみました。
データは、TidyTuesdayのcoffeeです。
library(tidyverse)
library(ggplot2)
coffee <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-07-07/coffee_ratings.csv')
head(coffee)
> head(coffee)
# A tibble: 6 x 43
total_cup_points species owner country_of_orig~ farm_name lot_number mill ico_number company altitude region
<dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 90.6 Arabica meta~ Ethiopia "metad p~ NA meta~ 2014/2015 metad ~ 1950-22~ guji-~
2 89.9 Arabica meta~ Ethiopia "metad p~ NA meta~ 2014/2015 metad ~ 1950-22~ guji-~
3 89.8 Arabica grou~ Guatemala "san mar~ NA NA NA NA 1600 - ~ NA
4 89 Arabica yidn~ Ethiopia "yidneka~ NA wole~ NA yidnek~ 1800-22~ oromia
5 88.8 Arabica meta~ Ethiopia "metad p~ NA meta~ 2014/2015 metad ~ 1950-22~ guji-~
6 88.8 Arabica ji-a~ Brazil NA NA NA NA NA NA NA
# ... with 32 more variables: producer <chr>, number_of_bags <dbl>, bag_weight <chr>, in_country_partner <chr>,
# harvest_year <chr>, grading_date <chr>, owner_1 <chr>, variety <chr>, processing_method <chr>, aroma <dbl>,
# flavor <dbl>, aftertaste <dbl>, acidity <dbl>, body <dbl>, balance <dbl>, uniformity <dbl>, clean_cup <dbl>,
# sweetness <dbl>, cupper_points <dbl>, moisture <dbl>, category_one_defects <dbl>, quakers <dbl>, color <chr>,
# category_two_defects <dbl>, expiration <chr>, certification_body <chr>, certification_address <chr>,
# certification_contact <chr>, unit_of_measurement <chr>, altitude_low_meters <dbl>, altitude_high_meters <dbl>,
# altitude_mean_meters <dbl>まずはふつうのボックスプロット
g <- coffee %>%
drop_na(any_of("country_of_origin")) %>%
filter(aroma != 0 & !country_of_origin %in% c("Zambia", "Rwanda", "Papua New Guinea", "Japan", "Mauritius", "Cote d?Ivoire")) %>%
ggplot(aes(x = country_of_origin, y = total_cup_points, color = country_of_origin)) +
coord_flip() +
labs(x = NULL, y = "Total cup points", size = 5) +
theme(
legend.position = "none",
axis.title = element_text(size = 14),
axis.text.x = element_text(family = "Roboto Mono", size = 10),
axis.text.y = element_text(family = "Roboto Mono", size = 10),
panel.grid = element_blank()
)
g +
geom_boxplot(color = "gray80", outlier.alpha = 0)
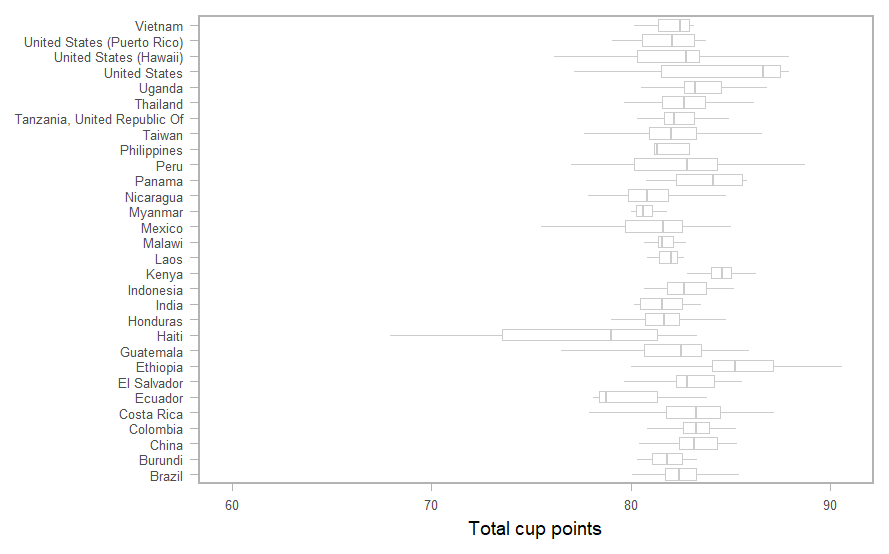
色付けるだけでもキレイに見えます。
set.seed(123) g + geom_boxplot(color = "gray80", outlier.alpha = 0) + geom_jitter(size = 1, alpha = 0.25, width = 0.2) + stat_summary(fun = mean, geom = "point", size = 4)
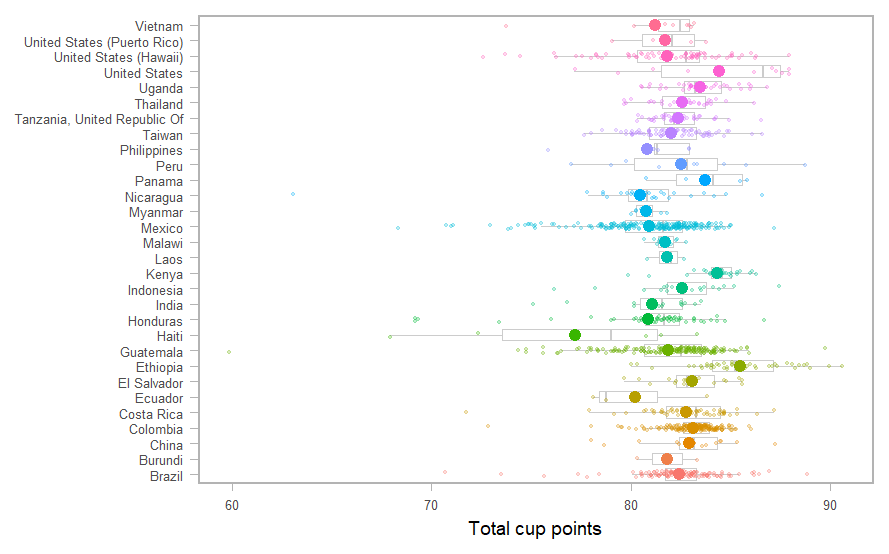
平均の線を入れてみたりします。
coffee_avg <- coffee %>% summarize(avg = mean(total_cup_points, na.rm = T)) %>% pull(avg) g + geom_hline(aes(yintercept = coffee_avg), color = "gray50", size = 0.6) + stat_summary(fun = mean, geom = "point", size = 4) + geom_jitter(size = 2, alpha = 0.25, width = 0.2)
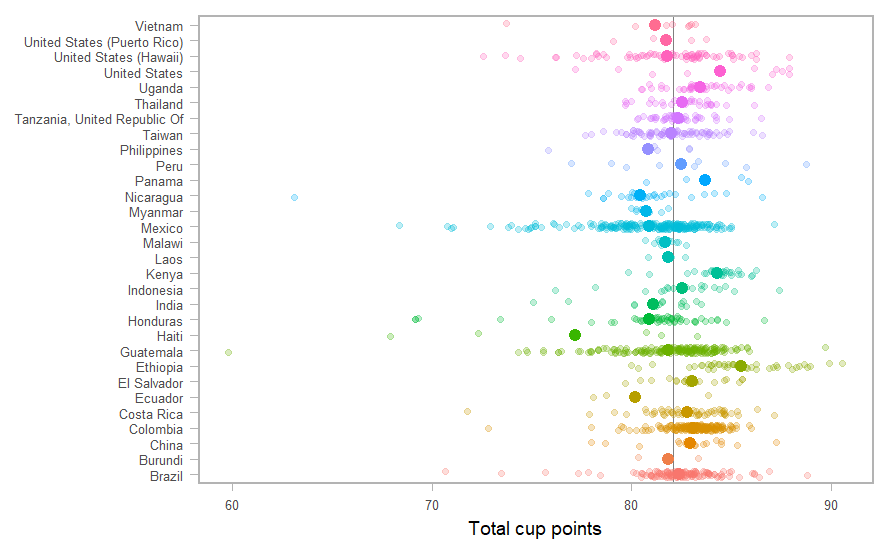
アノテーションと矢印いれるともっとわかりやすい。調整は面倒。。。
(g_text <-
g +
geom_hline(aes(yintercept = coffee_avg), color = "gray50", size = 0.6) +
stat_summary(fun = mean, geom = "point", size = 4) +
geom_jitter(size = 1, alpha = 0.25, width = 0.2) +
annotate(
"text", x = 16.3, y = 88, family = "Poppins", size = 3, color = "gray20", lineheight = .6,
label = glue::glue("Worldwide average:\n{round(coffee_avg, 1)} ")
) +
annotate(
"text", x = 11.5, y = 72, family = "Poppins", size = 3, color = "gray20",
label = "Each country's average"
)
)
arrows <-
tibble(
x1 = c(15.9, 11.5),
x2 = c(15.6, 10),
y1 = c(85, 75),
y2 = c(coffee_avg, 77)
)
g_text +
geom_curve(
data = arrows, aes(x = x1, y = y1, xend = x2, yend = y2),
arrow = arrow(length = unit(0.07, "inch")), size = 0.4,
color = "gray20", curvature = -0.3
)
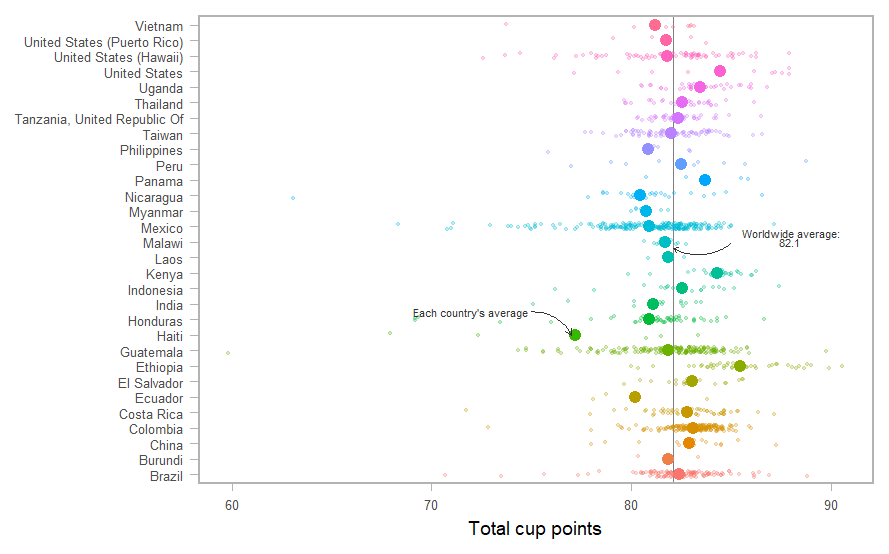
データは同じなのに、最初のボックスプロットとはかなり異なった印象です。
