【R】Kerasを使ってみる(iris)
1. はじめに
とにかく、慣れるためにたくさんの例をこなしていこうと思います。今回は、データサイエンスの定番データ(?)のirisを使って、KerasでDeep Learningしてみます。
RPubsにあったKeras on Iris data by Vincent Gaulを参考にさせていただきました。
2. さっそくやってみる
2.1 データの準備
library(tidyverse) library(keras) library(tensorflow) library(datasets) data(iris)
データは、matrixにしておく必要があります。また、matrixの要素はすべて同じ型になっている必要があります。このデータの場合、5列目(種類)が要因型ですから、0から始まる数値型にします(後ほど、one-hot encodeします。)。
iris[,5] <- as.numeric(iris[,5]) -1 iris <- as.matrix(iris) dimnames(iris) <- NULL
訓練データとテストデータに分けます。説明変数は1~4列で、目的変数が5列目です。
ind <- sample(2, nrow(iris), replace=TRUE, prob=c(0.67, 0.33)) iris.training <- iris[ind==1, 1:4] iris.test <- iris[ind==2, 1:4] iris.trainingtarget <- iris[ind==1, 5] iris.testtarget <- iris[ind==2, 5]
今回は、分類を行いますので、目的変数をBool型で処理できるようにone-hot encodingしておきます。Kerasでは、これを行う関数があり、to_categorical()です。変換したデータは、Labelsという変数名にし、最初のみ確認してみます。
iris.trainLabels <- to_categorical(iris.trainingtarget) iris.testLabels <- to_categorical(iris.testtarget) head(iris.testLabels)
> head(iris.testLabels)
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 1 0 0
[3,] 1 0 0
[4,] 1 0 0
[5,] 1 0 0
[6,] 1 0 02.2 モデル構築
続いてモデルの構築です。keras_model_sequential()関数で初期化します。まずは、最も簡単なニューラルネットワークとします。出力層は、0,1のBooleanを扱うためsoftmaxにします。
model <- keras_model_sequential() model %>% layer_dense(units = 8, activation = 'relu', input_shape = c(4)) %>% layer_dense(units = 3, activation = 'softmax') summary(model)
> summary(model)
Model: "sequential"
_________________________________________________________________________________________
Layer (type) Output Shape Param #
=========================================================================================
dense (Dense) (None, 8) 40
_________________________________________________________________________________________
dense_1 (Dense) (None, 3) 27
=========================================================================================
Total params: 67
Trainable params: 67
Non-trainable params: 0
_________________________________________________________________________________________2.3 コンパイルと学習
コンパイルします。
model %>% compile( loss = 'categorical_crossentropy', optimizer = 'adam', metrics = 'accuracy' )
学習します。
history <- model %>% fit( iris.training, iris.trainLabels, epochs = 200, batch_size = 5, validation_split = 0.2 )
エポック毎の学習の様子がプロットされていきます。
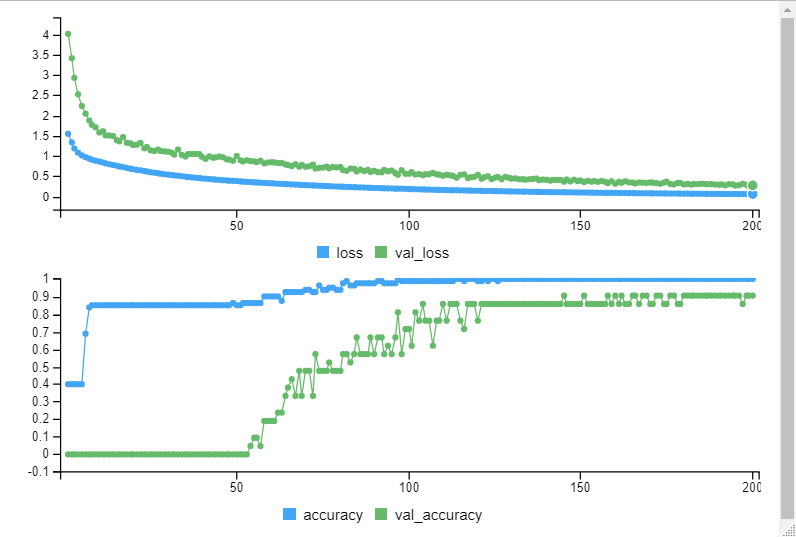
2.4 予測と評価
できたモデルにたいして、テストデータで予測してみます。その結果をConfusion matrixにて表示してみます。
classes <- model %>% predict_classes(iris.test, batch_size = 128) table(iris.testtarget, classes)
> table(iris.testtarget, classes)
classes
iris.testtarget 0 1 2
0 18 0 0
1 0 13 1
2 0 5 12かなり良い予測ができているようです。
テストデータでの結果を評価してみます。
score <- model %>% evaluate(iris.test, iris.testLabels, batch_size = 128) print(score)
> print(score)
$loss
[1] 0.2109397
$accuracy
[1] 0.8775519割近くの精度で予測てきているようですね。
できたモデルの書出し、読み込みは以下の通りです。jsonでも扱えます。
save_model_hdf5(model, "my_model.h5")
model <- load_model_hdf5("my_model.h5")
save_model_weights_hdf5(model, "my_model_weights.h5")
model %>% load_model_weights_hdf5("my_model_weights.h5")
json_string <- model_to_json(model)
model <- model_from_json(json_string)
2.5 最適化
もっと良い精度のモデルができないか、少しだけ最適化してみます。
まずは、レイヤーを増やしてみます。
model2 <- keras_model_sequential() model2 %>% layer_dense(units = 8, activation = 'relu', input_shape = c(4)) %>% layer_dense(units = 5, activation = 'relu') %>% layer_dense(units = 3, activation = 'softmax') model2 %>% compile( loss = 'categorical_crossentropy', optimizer = 'adam', metrics = 'accuracy' ) model2 %>% fit( iris.training, iris.trainLabels, epochs = 200, batch_size = 5, validation_split = 0.2 ) score2 <- model2 %>% evaluate(iris.test, iris.testLabels, batch_size = 128) print(score2)
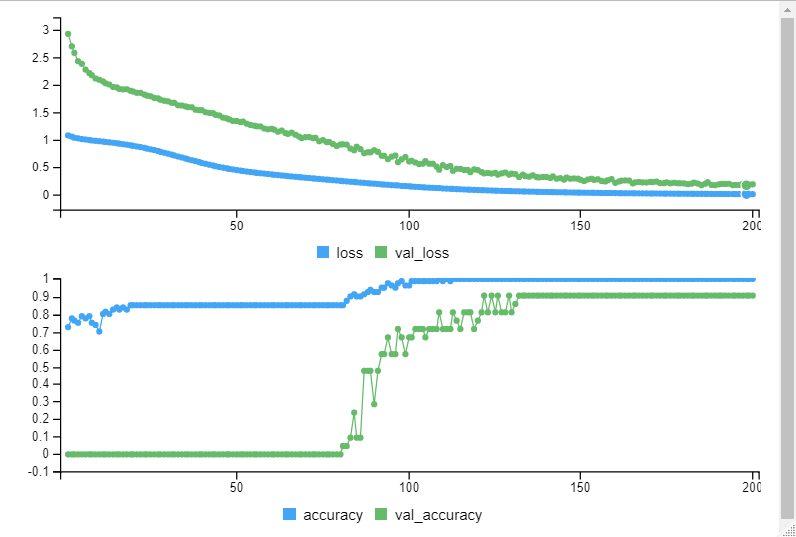
> print(score2)
$loss
[1] 0.2050286
$accuracy
[1] 0.877551Lossが若干減りました。
次に、入力の次元を少し大きくしてみます。
model3 <- keras_model_sequential() model3 %>% layer_dense(units = 28, activation = 'relu', input_shape = c(4)) %>% layer_dense(units = 3, activation = 'softmax') model3 %>% compile( loss = 'categorical_crossentropy', optimizer = 'adam', metrics = 'accuracy' ) model3 %>% fit( iris.training, iris.trainLabels, epochs = 200, batch_size = 5, validation_split = 0.2 ) score3 <- model3 %>% evaluate(iris.test, iris.testLabels, batch_size = 128) print(score3)
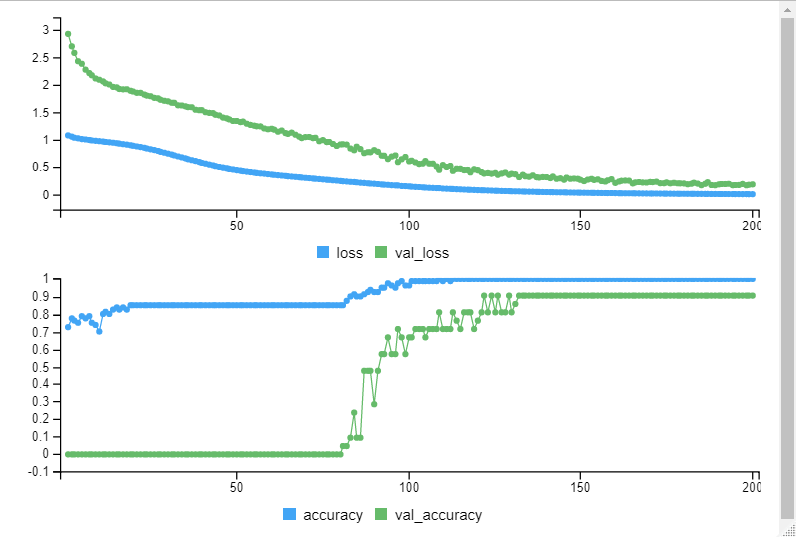
> print(score3)
$loss
[1] 0.1686141
$accuracy
[1] 0.8979592こちらも、Loss,Accuracyとも改善が見られました。
3. さいごに
Kerasを使うと簡単に結果が得られ、すぐに開発をしたいときには重宝しそうです。これからも、どんどん試してみたいと思います。
