【R】Tidymodels (random forest)
2020年10月30日
1. はじめに
Tidymodelsでいろいろ機械学習のお勉強。今回は、RandomForestを使って、カナダの発電用風車のタービンの大きさを予測。
データの取得・クリーニング等は、”Tune and interpret decision trees for #TidyTuesday wind turbines”こちらのサイト、機械学習に関しては、”tidymodelsによるtidyな機械学習(その3:ハイパーパラメータのチューニング)”と”tidymodelsとDALEXによるtidyで解釈可能な機械学習”のサイトを参考にさせていただきました。
2. やってみる
2.1 データ
データを取得し、きれいにします。
library(tidyverse)
turbines <- read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-10-27/wind-turbine.csv")
turbines
# A tibble: 6,698 x 15
objectid province_territ~ project_name total_project_c~ turbine_identif~ turbine_number_~
<dbl> <chr> <chr> <dbl> <chr> <chr>
1 1 Alberta Optimist Wi~ 0.9 OWE1 1/2
2 2 Alberta Castle Rive~ 44 CRW1 1/60
3 3 Alberta Waterton Wi~ 3.78 WWT1 1/6
4 4 Alberta Waterton Wi~ 3.78 WWT2 2/6
5 5 Alberta Waterton Wi~ 3.78 WWT3 3/6
6 6 Alberta Waterton Wi~ 3.78 WWT4 4/6
7 7 Alberta Cowley North 19.5 CON1 1/15
8 8 Alberta Cowley North 19.5 CON2 2/15
9 9 Alberta Cowley North 19.5 CON3 3/15
10 10 Alberta Cowley North 19.5 CON4 4/15
# ... with 6,688 more rows, and 9 more variables: turbine_rated_capacity_k_w <dbl>,
# rotor_diameter_m <dbl>, hub_height_m <dbl>, manufacturer <chr>, model <chr>,
# commissioning_date <chr>, latitude <dbl>, longitude <dbl>, notes <chr>turbines_df <- turbines %>%
transmute(
turbine_capacity = turbine_rated_capacity_k_w,
rotor_diameter_m,
hub_height_m,
commissioning_date = parse_number(commissioning_date),
province_territory = fct_lump_n(province_territory, 10),
model = fct_lump_n(model, 10)
) %>%
filter(!is.na(turbine_capacity)) %>%
mutate_if(is.character, factor)
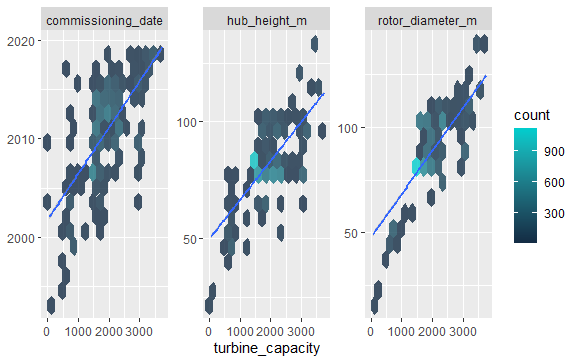
turbines_df %>%
select(turbine_capacity:commissioning_date) %>%
pivot_longer(rotor_diameter_m:commissioning_date) %>%
ggplot(aes(turbine_capacity, value)) +
geom_hex(bins = 15, alpha = 0.8) +
geom_smooth(method = "lm") +
facet_wrap(~name, scales = "free_y") +
labs(y = NULL) +
scale_fill_gradient(high = "cyan3")
学習用、テスト用のデータの準備とクロスバリデーション用のデータの準備。
library(tidymodels)
set.seed(123)
wind_split <- initial_split(turbines_df, strata = turbine_capacity)
wind_train <- training(wind_split)
wind_test <- testing(wind_split)
set.seed(234)
wind_folds <- vfold_cv(wind_train, strata = turbine_capacity)
wind_folds
> wind_folds
# 10-fold cross-validation using stratification
# A tibble: 10 x 2
splits id
<list> <chr>
1 <split [4.4K/488]> Fold01
2 <split [4.4K/487]> Fold02
3 <split [4.4K/486]> Fold03
4 <split [4.4K/486]> Fold04
5 <split [4.4K/486]> Fold05
6 <split [4.4K/486]> Fold06
7 <split [4.4K/486]> Fold07
8 <split [4.4K/486]> Fold08
9 <split [4.4K/485]> Fold09
10 <split [4.4K/484]> Fold102.2 モデル
ランダムフォレストを使ってみます。パラメータは、mtryとmin_nをチューニングします。
rf_spec <- rand_forest(
mtry = tune(),
min_n = tune()
) %>%
set_engine("ranger") %>%
set_mode("regression")
rf_spec
> rf_spec
Random Forest Model Specification (regression)
Main Arguments:
mtry = tune()
min_n = tune()
Computational engine: ranger rec = recipe(turbine_capacity ~ ., data = wind_train)
params = list(min_n(),
mtry() %>% finalize(rec %>% prep() %>% juice() %>% select(-turbine_capacity))) %>%
parameters()
rf_grid = params %>%
grid_random(size = 10)
2.3 学習
doParallel::registerDoParallel() set.seed(345) rf_rs <- tune_grid( rf_spec, turbine_capacity ~ ., resamples = wind_folds, grid = rf_grid, metrics = metric_set(rmse, rsq, mae, mape) ) rf_rs
# Tuning results
# 10-fold cross-validation using stratification
# A tibble: 10 x 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [4.4K/488]> Fold01 <tibble [40 x 6]> <tibble [0 x 1]>
2 <split [4.4K/487]> Fold02 <tibble [40 x 6]> <tibble [0 x 1]>
3 <split [4.4K/486]> Fold03 <tibble [40 x 6]> <tibble [0 x 1]>
4 <split [4.4K/486]> Fold04 <tibble [40 x 6]> <tibble [0 x 1]>
5 <split [4.4K/486]> Fold05 <tibble [40 x 6]> <tibble [0 x 1]>
6 <split [4.4K/486]> Fold06 <tibble [40 x 6]> <tibble [0 x 1]>
7 <split [4.4K/486]> Fold07 <tibble [40 x 6]> <tibble [0 x 1]>
8 <split [4.4K/486]> Fold08 <tibble [40 x 6]> <tibble [0 x 1]>
9 <split [4.4K/485]> Fold09 <tibble [40 x 6]> <tibble [0 x 1]>
10 <split [4.4K/484]> Fold10 <tibble [40 x 6]> <tibble [0 x 1]>
2.4 評価
rf_rs %>% collect_metrics()
> rf_rs %>% collect_metrics()
# A tibble: 40 x 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 3 25 mae standard 15.5 10 0.688 Model01
2 3 25 mape standard 0.973 10 0.0906 Model01
3 3 25 rmse standard 52.1 10 4.12 Model01
4 3 25 rsq standard 0.992 10 0.00114 Model01
5 2 8 mae standard 21.7 10 0.577 Model02
6 2 8 mape standard 1.14 10 0.0475 Model02
7 2 8 rmse standard 56.0 10 3.53 Model02
8 2 8 rsq standard 0.991 10 0.00105 Model02
9 4 19 mae standard 12.1 10 0.694 Model03
10 4 19 mape standard 0.652 10 0.0477 Model03
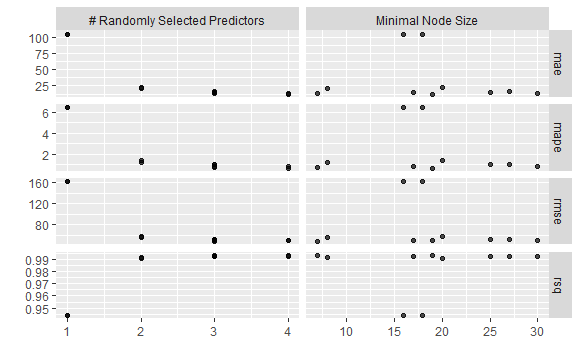
# ... with 30 more rows良いモデル順に表示してみます。
rf_rs %>% show_best(metric = "rmse", n_top = 3, maximize = FALSE)
# A tibble: 5 x 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 3 7 rmse standard 47.6 10 3.62 Model09
2 4 19 rmse standard 49.3 10 4.06 Model03
3 3 17 rmse standard 50.7 10 4.15 Model06
4 4 30 rmse standard 50.9 10 4.04 Model05
5 3 25 rmse standard 52.1 10 4.12 Model01プロットしてみます。
rf_rs %>% autoplot
最も良いパラメータをセットします。
rf_best_param <- rf_rs %>% select_best(metric = "rmse", maximize = FALSE) rf_best_param rf_model_best <- update(rf_spec, rf_best_param %>% select(-.config)) rf_model_best
Random Forest Model Specification (regression)
Main Arguments:
mtry = 3
min_n = 7
Computational engine: ranger final_rf <- finalize_model(rf_spec, select_best(rf_rs, "rmse")) final_rf
> final_rf
Random Forest Model Specification (regression)
Main Arguments:
mtry = 3
min_n = 7
Computational engine: ranger どれが重要なパラメータか、見てみます。
library(DALEX) #解釈
library(ingredients) #解釈
explainer = explain(final_fit,
data = turbines_df %>% select(-turbine_capacity),
y = turbines_df %>% pull(turbine_capacity),
label = "Random Forest")
fi = feature_importance(explainer,
loss_function = loss_root_mean_square, # 精度の評価関数
type = "raw")
fi
> fi
variable mean_dropout_loss label
1 _full_model_ 43.99775 Random Forest
2 province_territory 126.46790 Random Forest
3 hub_height_m 179.46859 Random Forest
4 model 231.70621 Random Forest
5 commissioning_date 264.15458 Random Forest
6 rotor_diameter_m 609.80586 Random Forest
7 _baseline_ 855.18911 Random Forestbaselineが最も影響があるんですかね。
