【R】tidytext
2021年7月6日
1. はじめに
tidytextは、tidyなルールを使って、テキストマイニングの手助けをしてくれるパッケージです。
2. インストール
CRANからインストールできます。
install.packages("tidytext")3. つかってみる
データとして、janeaustenrを使います。一行に一文となっており、扱いやすいです。
まず、読み込みます。
library(janeaustenr) library(tidyverse) original_books <- austen_books() %>% group_by(book) %>% mutate(line = row_number()) %>% ungroup() original_books
# A tibble: 73,422 x 3
text book line
<chr> <fct> <int>
1 "SENSE AND SENSIBILITY" Sense & Sensibility 1
2 "" Sense & Sensibility 2
3 "by Jane Austen" Sense & Sensibility 3
4 "" Sense & Sensibility 4
5 "(1811)" Sense & Sensibility 5
6 "" Sense & Sensibility 6
7 "" Sense & Sensibility 7
8 "" Sense & Sensibility 8
9 "" Sense & Sensibility 9
10 "CHAPTER 1" Sense & Sensibility 10
# ... with 73,412 more rows一行に一語のデータに変換します。これには、unnest_tokens()関数を使います。
library(tidytext) tidy_books <- original_books %>% unnest_tokens(word, text) tidy_books
> tidy_books
# A tibble: 725,055 x 3
book line word
<fct> <int> <chr>
1 Sense & Sensibility 1 sense
2 Sense & Sensibility 1 and
3 Sense & Sensibility 1 sensibility
4 Sense & Sensibility 3 by
5 Sense & Sensibility 3 jane
6 Sense & Sensibility 3 austen
7 Sense & Sensibility 5 1811
8 Sense & Sensibility 10 chapter
9 Sense & Sensibility 10 1
10 Sense & Sensibility 13 the
# ... with 725,045 more rowsstop words を除去します。
tidy_books <- tidy_books %>% anti_join(get_stopwords())
文字のカウントもできます。
tidy_books %>% count(word, sort = TRUE)
# A tibble: 14,375 x 2
word n
<chr> <int>
1 mr 3015
2 mrs 2446
3 must 2071
4 said 2041
5 much 1935
6 miss 1855
7 one 1831
8 well 1523
9 every 1456
10 think 1440
# ... with 14,365 more rowsinnor_joinの中でセンチメントアナリシスができます。
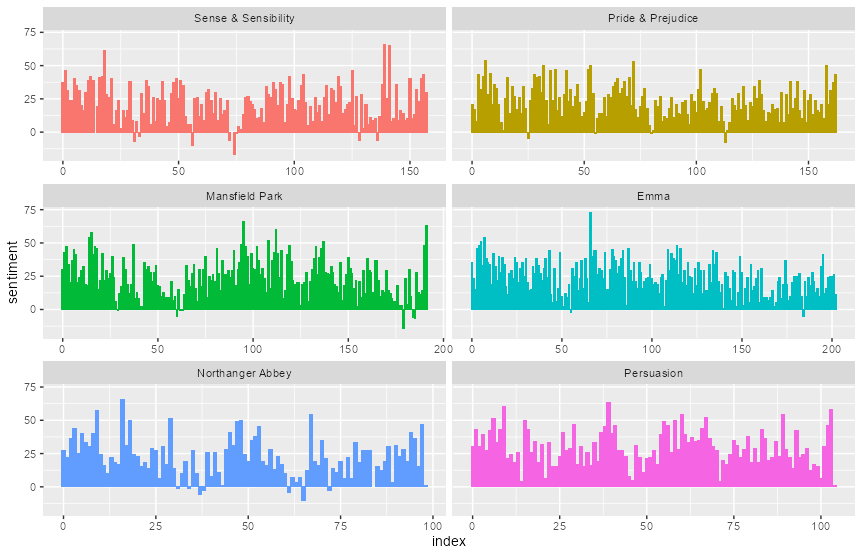
sentiment<-get_sentiments("nrc")
janeaustensentiment <- tidy_books %>%
inner_join(get_sentiments("nrc"), by = "word") %>%
count(book, index = line %/% 80, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)
janeaustensentiment
ggplotでプロットしてみます。
library(ggplot2) ggplot(janeaustensentiment, aes(index, sentiment, fill = book)) + geom_bar(stat = "identity", show.legend = FALSE) + facet_wrap(~book, ncol = 2, scales = "free_x")
4. さいごに
tidyにテキストマイニングができて気持ちいいです。
