【R】データクリーニング
データ分析のお仕事で一番時間がかかるのが、生データを分析できるデータにしてあげるクリーニングらしいです。なんと、8割の時間をデータクリーニングに費やしているとか。。。なので、これを手早くチャチャっとできたら、うれしいです。僕は詳しくないので、勉強してみました。でも、1回ぐらい勉強したぐらいでは全然だめで、何回も実践しないとダメでしょうねえ。
What It Takes to Tidy Census Dataというページを見ながらお勉強したときの備忘録です。コードは、ほぼほぼまんまです。
1. データ
アメリカのセンサスのデータ(MS-Excel 形式)を使わせてもらいます。きちんとしたデータですけど、やっぱり分析には使いにくい点が多くあります。日本の官庁のようにPDFになってないので良いのですが。
データ処理には、tidyverseを使います。
library(tidyverse)
library(readxl)
library(httr)
GET("https://www2.census.gov/programs-surveys/demo/tables/hhp/2020/wk2/educ2_week2.xlsx", write_disk(path <- tempfile(fileext = ".xlsx")))
census_sheet1 <- read_excel(path, sheet = 1)
これでデータを取り込めましたが、先頭3行が不要なのでSkipします。
census_sheet1 <- read_excel(path, sheet = 1, skip = 3)
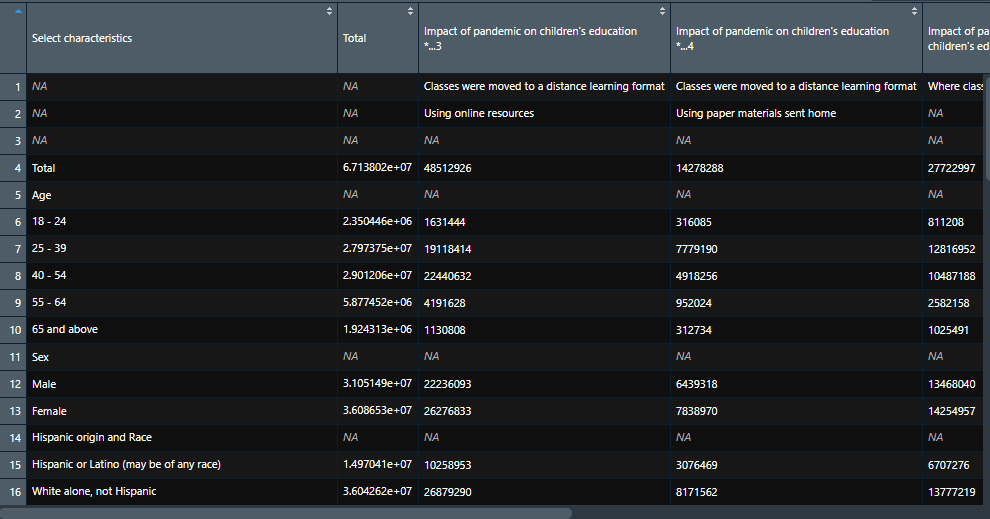
2. データクリーニング
2.1 単シート
いよいよ処理していきます。まずは、Column名を付けます。
col_names <-
c("select_characteristics", "total", "using_online_resources", "using_paper_materials_sent_home", "where_classes_were_cancelled", "where_classes_changed_in_another_way", "where_no_change_to_classes", "did_not_respond")
census_dat <-
census_sheet1 %>%
set_names(col_names)
また、上下に要らないデータがあるのでSliceします。
census_dat <- census_dat %>% slice(-1:-4, -61)
データ内容(”Age”, “Sex”, “Hispanic origin and Race”,・・・)毎にフィルタリングしてまとめます。
filter_var <-
c("Age", "Sex", "Hispanic origin and Race", "Education", "Marital status", "Presence of children under 18 years old", "Respondent or household member experienced loss of employment income", "Mean weekly hours spent on…", "Respondent currently employed", "Food sufficiency for households prior to March 13, 2020", "Household income")
census_dat <-
census_dat %>%
filter(!select_characteristics %in% filter_var)
カテゴリごとのColumnを追加します。
category_column <-
c("age", "age", "age", "age", "age", "sex", "sex", "race", "race", "race", "race", "race", "education", "education", "education", "education", "marital_status", "marital_status", "marital_status", "marital_status", "marital_status", "children", "children", "loss_employment", "loss_employment", "loss_employment", "hours_spent", "hours_spent", "employed", "employed", "employed", "food_sufficiency", "food_sufficiency", "food_sufficiency", "food_sufficiency", "food_sufficiency", "income", "income", "income", "income", "income", "income", "income", "income", "income")
census_dat <-
census_dat %>%
add_column(category_column)
キャラクタデータになっているColumnを数値に変換します。
census_dat <- census_dat %>% mutate_at(vars(total, using_online_resources:did_not_respond), list(~ as.numeric(.)))
これで、分析に利用できるキレイなデータになりました!
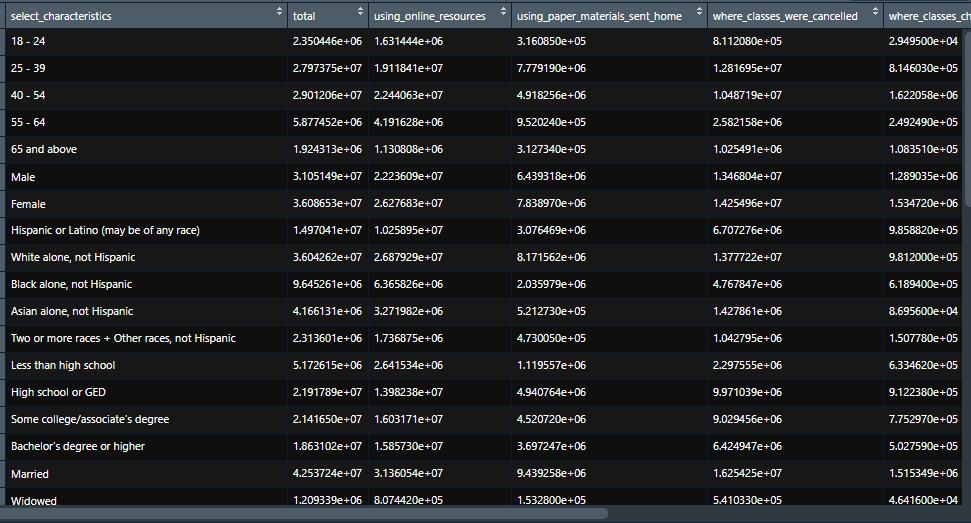
3.2 複数シート
前章で単シートの処理はできましたが、実際のExcelファイルは66シートもあります!!!これを1つ1つ手作業で・・・なんてできません。
そこで、map()をうまく使って複数シートを処理します。
まず、シートのリストを作ります。
census_list <- path %>% excel_sheets() %>% set_names() %>% map(~ read_excel(path = path, sheet = .x, skip = 3), .id = "Sheet")
その後、前章の単シートの処理と同じように各シートへ処理していきます。
census_list <- census_list %>% map(., set_names, nm = new_names) census_list <- census_list %>% map(~ slice(.x, -1:-4, -61)) census_list <- census_list %>% map(~ filter(.x, !select_characteristics %in% filter_var)) census_list <- census_list %>% map(~ add_column(.x, category_column)) census_list <- census_list %>% map(~ mutate_at(.x, vars(total, using_online_resources:did_not_respond), list(~ as.numeric(.))))
最後にデータフレームに格納します。
census_df <- census_list %>% map_df(~ as.data.frame(.x), .id = "state")
完成です!!!きれいなデータになりました!
3. データを使う
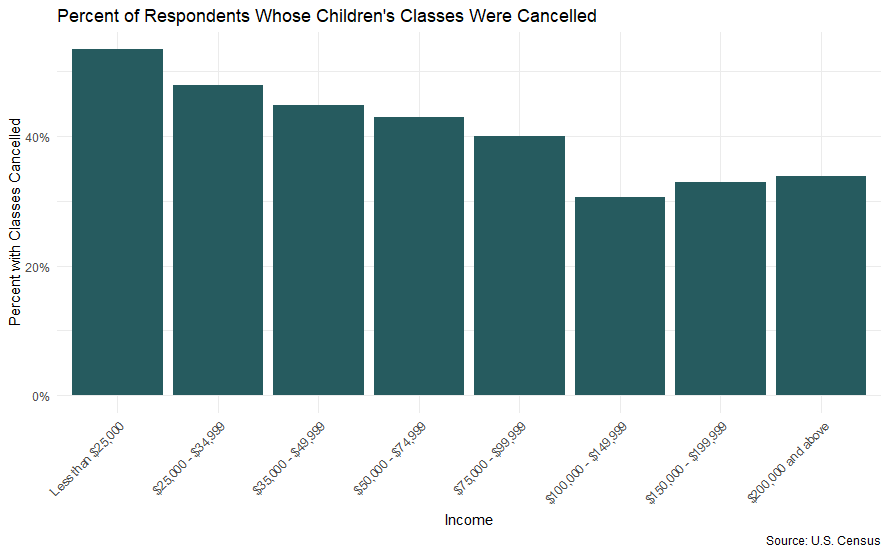
せっかくキレイなデータができたので、使ってみます。収入に応じてクラスのキャンセルがどれだけ出たかを表示してみます。
パーセンテージを計算します。
census_us_income <-
census_df %>%
filter(state == "US", category_column == "income") %>%
mutate(responses = case_when(!is.na(did_not_respond) ~ total - did_not_respond,
is.na(did_not_respond) ~ total),# calculate denominator
pct_cancelled = where_classes_were_cancelled / responses) # calculate percentage
収入毎に分けます。
census_us_income <- # setting factor levels so graph shows correct order
census_us_income %>%
mutate(select_characteristics = factor(select_characteristics,
levels = c("Less than $25,000",
"$25,000 - $34,999",
"$35,000 - $49,999",
"$50,000 - $74,999",
"$75,000 - $99,999",
"$100,000 - $149,999",
"$150,000 - $199,999",
"$200,000 and above")))
プロットします。
census_us_income %>%
filter(select_characteristics != "Did not report") %>%
ggplot(aes(x = select_characteristics, y = pct_cancelled)) +
geom_bar(stat = "identity",
fill = "#265B5F") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_y_continuous(labels = scales::percent) +
labs(title = "Percent of Respondents Whose Children's Classes Were Cancelled",
x = "Income",
y = "Percent with Classes Cancelled",
caption = "Source: U.S. Census")
4. さいごに
tidyverseすごいな。
