【R】RでKeras
1. はじめに
やっと、ディープラーニングの勉強に移れます。さっさとすれば良かったんだけど。。。
お手軽らしいのでKerasを使ってみます。TensorFlow, CNTK, Theanoをバックエンドとして利用するインターフェースであるKerasはPythonを介してRでも使えます。CPUとGPUも使えます。
2. インストール
Kerasをインストールします。
devtools::install_github("rstudio/tensorflow")
install.packages("tensorflow")
library(tensorflow)
install_tensorflow(version="2.1.0")
devtools::install_github("rstudio/keras")
install.packages("keras")
library(keras)
install_keras()ここで、大きく躓きました。tensorflowのインストールは成功するのですが、いざ実行しようとするとエラーになります。こちらのページを参考に「Vusual C++ Build Tools 2019」をインストールすることで解決しました。これだけで、2日間もかけてしまった。。。。また、僕のマシンでは、Tensorflow 2.1.0しか動きませんでした。どうやらマシンによって制約があるようです。
3. 使ってみる
3.1 データの準備
データはKerasパッケージにあるcifar10というデータセットを利用します。これは、猫や車など10種類の画像データ60000枚が32×32のカラーイメージで納められており、すでにトレーニング用50000枚とテスト用10000枚に分けられています。各種類6000枚の画像となっています。今回は、10種類すべてを扱うのが大変だったので、0~3の4種類の画像のみを用いてディープラーニングを行ってみます。
まず、データの準備です。データを読み込み、データはRGB値1~255ですので、255で割って正規化します。また、ラベルデータはone-hotデータに変更します。
cifar10 <- cifar10_data x_train = cifar10$train$x[cifar10$train$y %in% c(0,1,2,3), , ,]/255 x_test = cifar10$test$x[cifar10$test$y %in% c(0,1,2,3), , ,]/255 y_train = to_categorical(cifar10$train$y[cifar10$train$y %in% c(0,1,2,3)], num_classes = 10) y_test = to_categorical(cifar10$test$y[cifar10$test$y %in% c(0,1,2,3)], num_classes = 10)
実際にどのようなデータがあるかを表示してみます。EBImageパッケージを利用するので、インストールしていない場合はインストールします。
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("EBImage")
#イメージの表示
library(EBImage)
pictures <- c(102, 5, 7, 40, 4, 28,1, 8, 9, 22) #表示させるイメージの番号
fig_img <- list()
for (i in 1:10 ) {
fig_mat = cifar10$train$x[pictures[i], , , ]
fig_img[[i]] <- normalize(Image(transpose(fig_mat), dim=c(32,32,3), colormode='Color'))
}
fig_img_comb <- combine(fig_img[1:10])
fig_img_obj <- tile(fig_img_comb,5)
plot(fig_img_obj, all=T)

確かに粗い画像です。人間に目には、なんとなく何の画像かわかりますね。
3.2 モデル
モデルを準備します。今回は、畳み込みニューラルネットワークで画像を分類してみます。
畳み込みは、layer_conv_2d()、活性化関数はlayer_activation()、プーリング層はlayer_max_pooling_2d()です。また、全結合はlayer_dense()、ドロップアウトはlayer_dropout()で記述します。これらをパイプ%>%でつないでいきます。
最後にコンパイルします。
model %>%
## 畳み込み層
layer_conv_2d(
filter = 32, kernel_size = c(3,3), padding = "same",
input_shape = c(32, 32, 3)
) %>%
layer_activation("relu") %>%
## 畳み込み層
layer_conv_2d(filter = 32, kernel_size = c(3,3)) %>%
layer_activation("relu") %>%
## プーリング層 →
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_dropout(0.25) %>%
## 畳み込み層
layer_conv_2d(filter = 64, kernel_size = c(3,3), padding = "same") %>%
layer_activation("relu") %>%
## 畳み込み層
layer_conv_2d(filter = 64, kernel_size = c(3,3)) %>%
layer_activation("relu") %>%
## プーリング層
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_dropout(0.25) %>%
## 全結合
layer_flatten() %>%
layer_dense(512) %>%
layer_activation("relu") %>%
##dropout
layer_dropout(0.5) %>%
layer_dense(10) %>%
layer_activation("softmax") %>%
compile(
loss = "categorical_crossentropy",
optimizer = optimizer_rmsprop(lr = 0.0001, decay = 1e-6),
metrics = "accuracy")
3.3 学習と評価
学習は、fit()で行います。
model_trained <- model %>% fit( x_train, y_train, batch_size = 32, epochs = 10, validation_data = list(x_test, y_test), shuffle = TRUE )
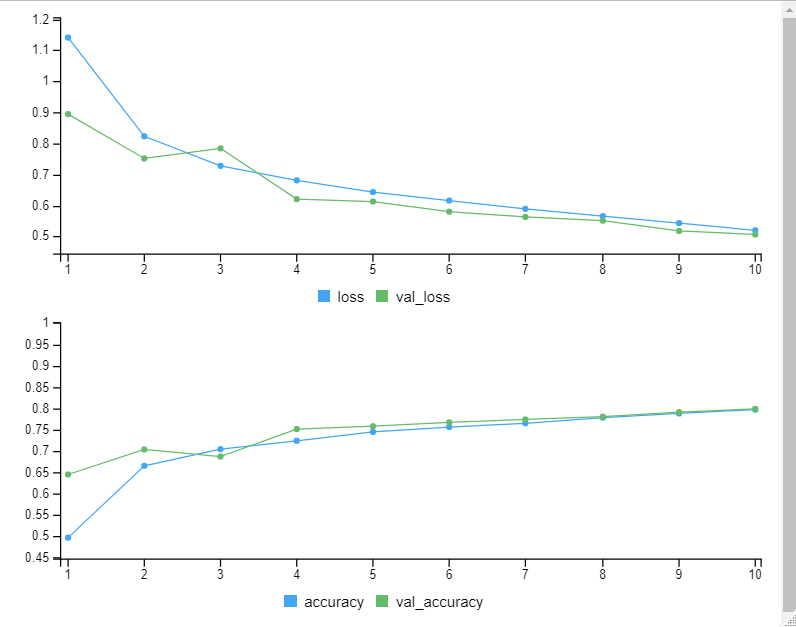
> model_trained <- model %>% fit(
+ x_train, y_train,
+ batch_size = 32,
+ epochs = 10,
+ validation_data = list(x_test, y_test),
+ shuffle = TRUE
+ )
Train on 20000 samples, validate on 4000 samples
Epoch 1/10
20000/20000 [==============================] - 117s 6ms/sample - loss: 1.1411 - accuracy: 0.4971 - val_loss: 0.8944 - val_accuracy: 0.6450
Epoch 2/10
20000/20000 [==============================] - 97s 5ms/sample - loss: 0.8230 - accuracy: 0.6654 - val_loss: 0.7516 - val_accuracy: 0.7035
Epoch 3/10
20000/20000 [==============================] - 99s 5ms/sample - loss: 0.7277 - accuracy: 0.7042 - val_loss: 0.7840 - val_accuracy: 0.6870
Epoch 4/10
20000/20000 [==============================] - 101s 5ms/sample - loss: 0.6811 - accuracy: 0.7239 - val_loss: 0.6207 - val_accuracy: 0.7513
Epoch 5/10
20000/20000 [==============================] - 94s 5ms/sample - loss: 0.6434 - accuracy: 0.7446 - val_loss: 0.6127 - val_accuracy: 0.7580
Epoch 6/10
20000/20000 [==============================] - 93s 5ms/sample - loss: 0.6159 - accuracy: 0.7561 - val_loss: 0.5800 - val_accuracy: 0.7670
Epoch 7/10
20000/20000 [==============================] - 94s 5ms/sample - loss: 0.5891 - accuracy: 0.7649 - val_loss: 0.5631 - val_accuracy: 0.7738
Epoch 8/10
20000/20000 [==============================] - 96s 5ms/sample - loss: 0.5658 - accuracy: 0.7783 - val_loss: 0.5510 - val_accuracy: 0.7803
Epoch 9/10
20000/20000 [==============================] - 100s 5ms/sample - loss: 0.5433 - accuracy: 0.7878 - val_loss: 0.5180 - val_accuracy: 0.7910
Epoch 10/10
20000/20000 [==============================] - 91s 5ms/sample - loss: 0.5201 - accuracy: 0.7969 - val_loss: 0.5068 - val_accuracy: 0.7987各エポックでlossと精度を計算してくれます。80%というのは良いのではないでしょうか?
モデルの保存や呼び出しは以下の通りです。
saveRDS(model_trained, "model_trained.rds")
read_model <- readRDS("model_trained.rds")
3.4 テストデータで検証
できたモデルをテストデータにて検証します。
acc_loadmymodel <- model %>% evaluate(x_test, y_test) acc_loadmymodel
> acc_loadmymodel
$loss
[1] 0.5068229
$accuracy
[1] 0.7987580%程度の正解率なら良いのではないでしょうか?
3.5 評価
評価してみます。
実際の予測結果は以下の通り。
pred = model %>% predict_classes(x_test)
pred11 = (pred +1)
y_actu = NA
for (kk in 1: dim(y_test)[1] ) {
actlist = which(y_test[kk,] == 1)
y_actu = append( y_actu, actlist )
}
y_actu = y_actu[-1]
> y_actu
[1] 4 1 2 4 2 1 1 3 1 3 2 1 4 1 4 4 4 3 2 3 4 3 1 3 4 4 2 2 3 3 1 4 1 1 4 2 2 4 1 3 2 4 1 3 4 2 3 1
[49] 4 3 2 2 3 3 4 3 3 1 1 3 3 2 1 4 1 1 3 3 4 4 1 1 2 3 2 2 4 1 1 3 4 2 1 1 2 2 1 4 2 3 3 4 1 4 1 1
[97] 2 1 3 1 3 4 4 1 4 4 1 2 1 2 1 2 3 4 1 1 4 3 2 3 2 1 1 4 3 4 2 2 4 4 1 3 3 2 1 3 3 4 3 1 2 2 4 2
[145] 3 1 1 1 3 3 3 2 3 3 3 4 1 4 1 2 3 4 2 1 4 1 1 3 4 1 3 4 4 3 4 2 2 1 3 3 3 4 4 2 4 4 4 1 1 1 2 1
[193] 2 2 1 3 3 1 2 4 1 1 1 1 1 3 1 2 2 3 4 3 1 3 3 4 3 2 4 1 1 4 3 2 4 4 1 3 2 4 4 3 2 2 3 2 3 4 1 4
[241] 1 2 4 4 3 2 2 2 4 1 2 4 4 4 3 1 4 2 1 4 1 4 3 3 4 3 3 3 4 4 2 3 2 4 3 2 2 4 3 1 3 3 2 3 3 3 2 4
[289] 1 2 3 1 2 1 3 3 1 2 1 4 4 1 4 2 3 2 4 3 1 4 3 1 4 4 2 4 3 3 2 3 3 1 3 2 4 3 1 3 1 1 4 4 1 2 4 1
[337] 2 4 2 3 4 3 4 4 1 1 1 2 1 2 2 4 4 3 2 4 1 1 2 4 1 1 1 3 4 3 3 3 2 1 4 1 2 4 4 2 1 4 2 2 2 3 2 1
[385] 2 3 1 4 2 3 1 2 4 2 4 1 2 2 1 2 4 2 1 2 2 1 1 4 1 1 4 4 4 1 3 3 3 3 2 2 4 3 1 4 2 4 2 4 1 4 1 4
[433] 1 1 1 3 4 1 1 3 2 3 1 3 1 3 4 2 4 4 4 3 4 2 3 2 1 2 2 3 3 3 3 1 2 2 1 4 1 4 4 3 4 2 2 4 4 4 2 1
[481] 2 2 1 1 2 2 3 1 3 1 2 4 1 2 4 4 2 2 2 1 2 3 1 4 3 3 3 3 2 2 1 4 4 2 4 4 3 3 4 2 1 3 2 2 3 1 2 1
[529] 3 1 1 3 3 2 4 2 2 1 4 3 3 4 2 3 2 1 3 4 2 2 4 3 4 2 3 4 3 4 2 1 3 2 2 2 1 2 4 2 2 2 4 1 2 2 1 4
[577] 2 4 1 3 3 4 3 2 2 1 1 2 2 4 4 3 2 3 1 2 3 3 2 3 3 2 3 3 2 2 1 3 2 4 4 4 3 4 4 3 2 3 2 4 1 2 3 1
[625] 2 1 1 3 1 3 2 3 2 4 4 4 1 4 4 2 4 4 4 3 4 4 2 1 2 3 4 2 2 3 1 1 1 3 4 4 1 3 2 3 2 1 3 1 4 1 2 3
[673] 2 1 1 4 2 1 1 3 1 1 1 4 1 1 2 2 1 3 2 1 3 2 3 3 1 2 3 3 3 2 3 4 1 4 4 2 1 2 4 4 1 4 1 2 3 3 2 2
[721] 2 4 1 1 3 2 4 1 3 4 2 1 3 3 4 3 3 4 1 3 4 1 2 2 4 4 3 4 1 1 1 2 4 2 4 1 3 3 3 2 2 1 3 2 1 4 4 2
[769] 3 4 1 3 3 4 1 3 3 4 1 2 2 1 4 4 2 4 3 4 2 2 3 4 4 2 3 4 3 1 1 2 4 2 4 4 4 1 2 3 3 4 3 3 3 4 1 3
[817] 1 2 4 3 3 1 2 1 3 1 2 1 3 3 1 2 3 1 2 4 1 1 2 1 3 1 3 1 2 3 1 3 4 1 3 2 4 3 4 1 2 3 1 3 3 4 4 2
[865] 4 2 4 1 3 1 3 3 1 2 4 3 3 1 3 2 3 2 3 4 4 1 4 3 2 1 3 4 1 1 4 4 2 1 2 4 3 1 4 4 3 2 1 4 4 3 2 2
[913] 1 4 3 1 3 4 2 3 4 3 3 3 1 1 2 1 3 3 2 3 1 1 2 2 4 2 3 2 3 3 4 3 1 2 1 1 1 2 1 3 1 2 3 2 2 1 4 1
[961] 4 3 4 1 4 3 1 3 1 2 2 3 4 3 2 3 4 2 1 2 1 3 3 1 1 2 3 2 4 1 4 2 4 1 3 3 3 3 3 2
[ reached getOption("max.print") -- omitted 3000 entries ]Confusion matrixで見てみます。
library("caret")
confusionMatrix(as.factor(pred11), as.factor(y_actu))
> confusionMatrix(as.factor(pred11), as.factor(y_actu))
Confusion Matrix and Statistics
Reference
Prediction 1 2 3 4
1 769 25 69 16
2 61 922 16 21
3 100 22 712 129
4 70 31 203 834
Overall Statistics
Accuracy : 0.8092
95% CI : (0.7967, 0.8213)
No Information Rate : 0.25
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 0.7457
Mcnemar's Test P-Value : 6.085e-14
Statistics by Class:
Class: 1 Class: 2 Class: 3 Class: 4
Sensitivity 0.7690 0.9220 0.7120 0.8340
Specificity 0.9633 0.9673 0.9163 0.8987
Pos Pred Value 0.8749 0.9039 0.7394 0.7329
Neg Pred Value 0.9260 0.9738 0.9052 0.9420
Prevalence 0.2500 0.2500 0.2500 0.2500
Detection Rate 0.1923 0.2305 0.1780 0.2085
Detection Prevalence 0.2198 0.2550 0.2407 0.2845
Balanced Accuracy 0.8662 0.9447 0.8142 0.86634. さいごに
Kerasを使うと、直感的に手軽にディープラーニングを扱えますね。実用化するには、パラメータの最適化等を行う必要があると思いますが、まずは使用感を得られただけでも満足です。
